
A decision table organizes information to guide someone through a decision. The two main categories of information are the conditions (“if you have this…”) and the decisions — the actions to take (“…then do this”). Often there are multiple categories of conditions, as in this example, a decision table for calculating flood insurance premiums:
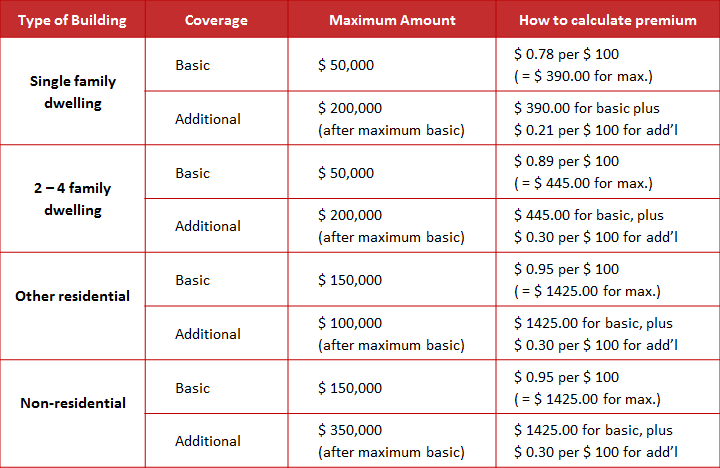
There are three categories of conditions: the type of building, the nature of the coverage, and the maximum amount of coverage. A set is my term for the combination of conditions that leads to a specific action. In the table above, “other residential,” “additional,” and “maximum $100,000” is a set that leads to a particular premium calculation ($ 1,425 plus $0.30 per $100 for coverage over $150,000).
This post will show you one technique for identifying conditions, grouping them into sets, and arranging that information into a useful decision table.
The goal
We want to build a decision table help our sales staff know what price to offer customers. You’ll notice that for this exercise it doesn’t matter what the products are, or even what the business is, as long as we can identify the conditions and the actions.
Step 1: List all the possible decisions.
The individual decisions are all the possible actions or outcomes for offering a price. There are three: the VIP discount, the courtesy discount, and the standard price.

You can start your analysis with conditions if you like, but in my experience it’s a lot easier to get agreement on the actions.
By the way, this job aid doesn’t deal with what the discounts are, just when to offer them. You can decide which price to offer without knowing how to compute that price–which underscores the need to think about the task you’re guiding. Maybe you have one job aid for a complex task (choosing and calculating the price), or maybe you have two (how to choose, and then how to calculate).
We’ll stick with a simple example.
Step 2: For each decision, list each set of conditions that applies.
A set is a list of the specific conditions that lead to a particular decision (When the person is already a customer and when his credit code is 1, then offer the VIP discount).
As you analyze the task, each set gets its own row, even if it leads to the same decision as another set.
Each condition in a set has its own column, with the decision in the rightmost column.

The example has three sets of conditions under which you offer the courtesy discount. Each set gets its own row. Repeating the decision this way highlights the different routes to reaching that decision.
Also, in a given set, all the conditions must be satisfied in order to trigger the decision. Being an existing customer is not by itself enough to justify the VIP discount; a price over $999 is.
The company’s procedures didn’t spell out “all others” as a specific type of customer; we derived that from what to do if a customer didn’t meet the conditions for either of the two discounts.
Step 3: Arrange similar conditions into columns.
 The information in this table is the same as in Step 2. The difference is that we’ve moved related conditions so they’re grouped in columns. Each column is a category–often pretty loose, at first, as you figure out what the various conditions are.
The information in this table is the same as in Step 2. The difference is that we’ve moved related conditions so they’re grouped in columns. Each column is a category–often pretty loose, at first, as you figure out what the various conditions are.
Step 4: Reorganize the conditions.
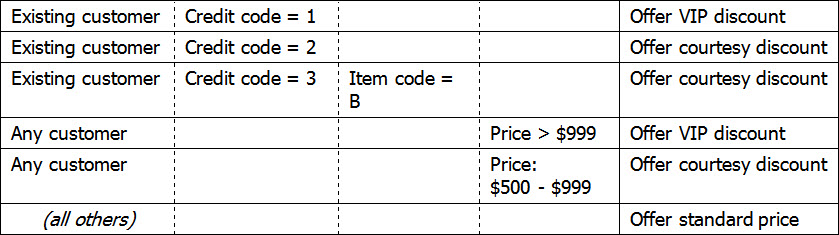
Some ways to do this:
Study the columns to see if one stands out as a first cut. If so, move it to the leftmost position. (In the example, Customer seemed like a good start, so it stayed on the left.)
Rearrange rows so identical conditions adjoin one another in that leftmost column.
Move to the next column. Again, consider rearranging the order of columns. You’re now filtering from a particular condition in the leftmost column. (In the example, there are three possible sets of conditions that apply to existing customers; two sets that apply to any customer.)
If you have more than four categories of conditions (more than four when columns), consider using multiple tables. If that were the case here, I might have two decision tables, one for existing customers and one for new ones.
Step 5: Add headings that make sense on the job.
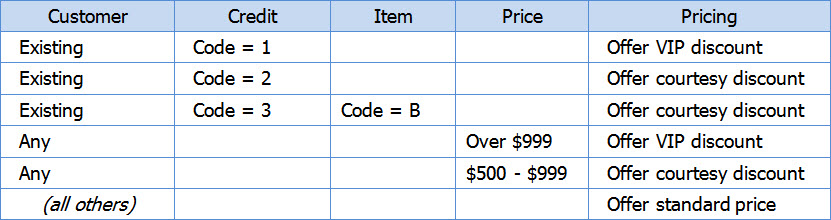
You might have had headings in the previous step–they’re a good way to guide analysis and tease out what a category is really about. Here, we’re moving from analysis to job aid, and so we want headings that help a person on the job.
It’s good to eliminate repetition, so we’re trying Customer and Credit as headings.
Here’s the next version: it pulls the word “code” out of four cells, making them easier to read.
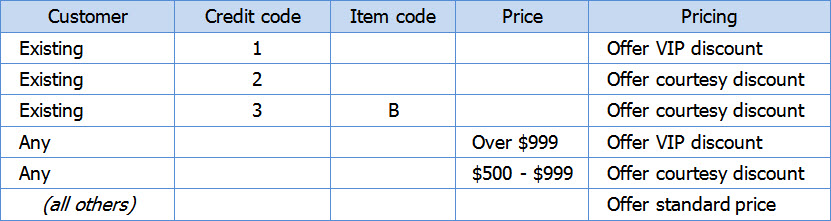
Step 6: Simplify the table.
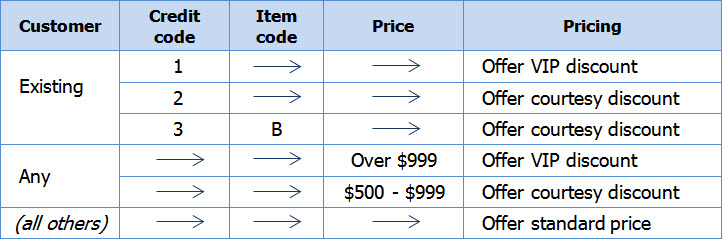
In the leftmost column, we’ve merged identical conditions. As a person consults this job aid, she’ll decide whether she’s dealing with an existing customer. If she’s not, she can ignore the three sub-paths.
Use dashes, arrows, shading, or similar formatting to make clear that certain conditions don’t apply.
Note that the example specifically did not merge the adjoining “courtesy discount” cells in the decision column. In many cases, I think it’s worth giving each set of conditions its own actions.
By the way, here’s the same decision table with the customer conditions switched:

The logic here is that for any customer, you can offer discounts based on price, and for an existing customer, you can also offer discounts based on other conditions. To facilitate this, I moved Price to the second column; it was the category most closely related to the first Customer condition (‘any’).
Those are the basics. Some thoughts about this approach:
- It’s a great analytic tool, especially when collaborating with others. Agreeing on the outcomes (Step 1) and working out sets of conditions (Step 2) can be frustrating and highly iterative, but progress is easy to spot.
- It’s a tool, not a law of physics. You can combine Step 2 (identifying sets) and Step 3 (organizing conditions into columns). If you’re doing this electronically, with a word processor or even a spreadsheet, it’s not much work to move things around as circumstances demand.
- It’s a great confirmation tool. Once you’ve got a working draft, a skilled performer or a subject-matter expert can try it out. Misunderstandings, omissions, and new sets of conditions emerge quickly.
this information has helped me as a student on how to build or develope decision tables. thanks very much
I’m glad you found it helpful, Maybin.